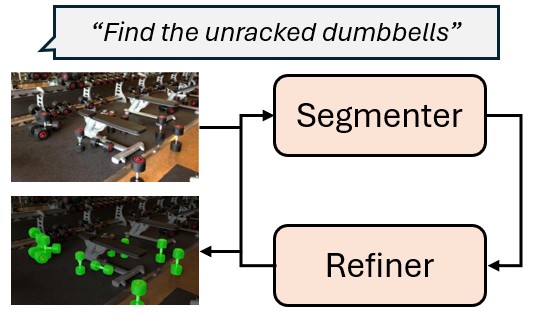
CoT-RVS: Zero-Shot Chain-of-Thought Reasoning Segmentation for Videos
International Conference on Learning Representations (ICLR), 2026
CoT-RVS extracts temporal-semantic correlation in videos with chain of thoughts and achieves state-of-the-art performance for reasoning video segmentation.